Experiment 28
I tested four bandit algorithms on news recommendation to figure out if contextual learning could teach LLMs to adapt their prompting style to individual users in real time.
Teaching LLMs to Learn What You Want (Using Bandit Algorithms)
The Problem
LLMs are weirdly sensitive to how you prompt them. Same question, different phrasing, completely different answer quality. Right now, most LLM apps use one static system prompt that developers tune by hand. It’s like A/B testing in 2010—slow, rigid, and treats everyone the same.
What if the system could learn your preferences in real time?
Bandits for Prompt Shaping
Here’s the idea: define a small set of shaping prompts—short directives that steer the LLM’s behavior. Each one is an “arm” in bandit terms. The system picks one, generates a response, observes how you react (ratings, engagement, follow-ups), and updates its beliefs about what works for you.
Example arms:
- “Validate the user’s perspective before responding” → supportive tone
- “Respectfully challenge assumptions” → Socratic pushback
- “Concise, factual statements only” → neutral and brief
- “Mirror the user’s energy” → adaptive empathy
A basic multi-armed bandit learns which strategy works best on average. But people are different. Someone venting wants validation. Someone stress-testing an idea wants pushback.
Contextual bandits solve this. They use features about the conversation—your message tone, topic, session history—to personalize which prompt gets selected. LinUCB (which I’ll explain below) could learn patterns like:
- Assertive messages → challenge assumptions (you want sparring)
- Frustrated tone → validate first (you need to feel heard)
- Rapid factual questions → concise answers (you want efficiency)
These are the interaction patterns that one-size-fits-all approaches miss entirely.
Why This Matters
The reward signal is messier than a click (maybe thumbs up/down, or whether you continue the conversation), and you need to handle preference shifts within a single session. But the core framework—pick an action, observe feedback, update—maps perfectly. And unlike news recommendation with thousands of articles, you only need 4-8 well-designed shaping prompts, so the bandit converges faster.
The catch: feature quality matters. Coarse features like “positive vs negative tone” won’t cut it. You need granular conversational signals to unlock real personalization.
Which brings me to the experiment.
Testing the Idea: News Recommendation
I wanted to see how much feature granularity actually matters, and whether contextual bandits justify their complexity. So I compared four algorithms on a simpler problem first: news recommendation.
The setup: 100,000 impression logs from Microsoft’s MIND dataset. Each round, the algorithm picks one article from ~37 candidates. If the user clicked it, reward = 1. Otherwise, 0. Same data, same order, for all four algorithms.
The Algorithms
RandomChoice – Pick randomly. No learning. This is the floor.
Epsilon-Greedy – Track average click rate per article. 90% of the time, pick the best one. 10% of the time, explore randomly. Simple, fast, no personalization.
Thompson Sampling – Bayesian approach. Maintains a probability distribution over each article’s true click rate. Samples from each distribution and picks the highest sample. Exploration happens automatically based on uncertainty. I used a Beta(1,8) prior calibrated to the ~11% base click rate, which helps with the 18k sparse articles.
LinUCB – The contextual algorithm. Builds a linear model per article that predicts clicks from a 62-dimensional context vector:
- First 31 dims: user profile (normalized frequency of subcategories in their click history)
- Last 31 dims: article subcategory (one-hot)
The MIND dataset has 285 subcategories. I kept the top 30 (covering 84% of articles) plus an “other” bucket. This lets LinUCB learn patterns like “NFL fans click NFL articles” instead of just “sports fans like sports.”
Key point: I initially tried 18 coarse categories and LinUCB barely beat epsilon-greedy. Switching to 285 subcategories made the difference. Feature granularity unlocks contextual algorithms.
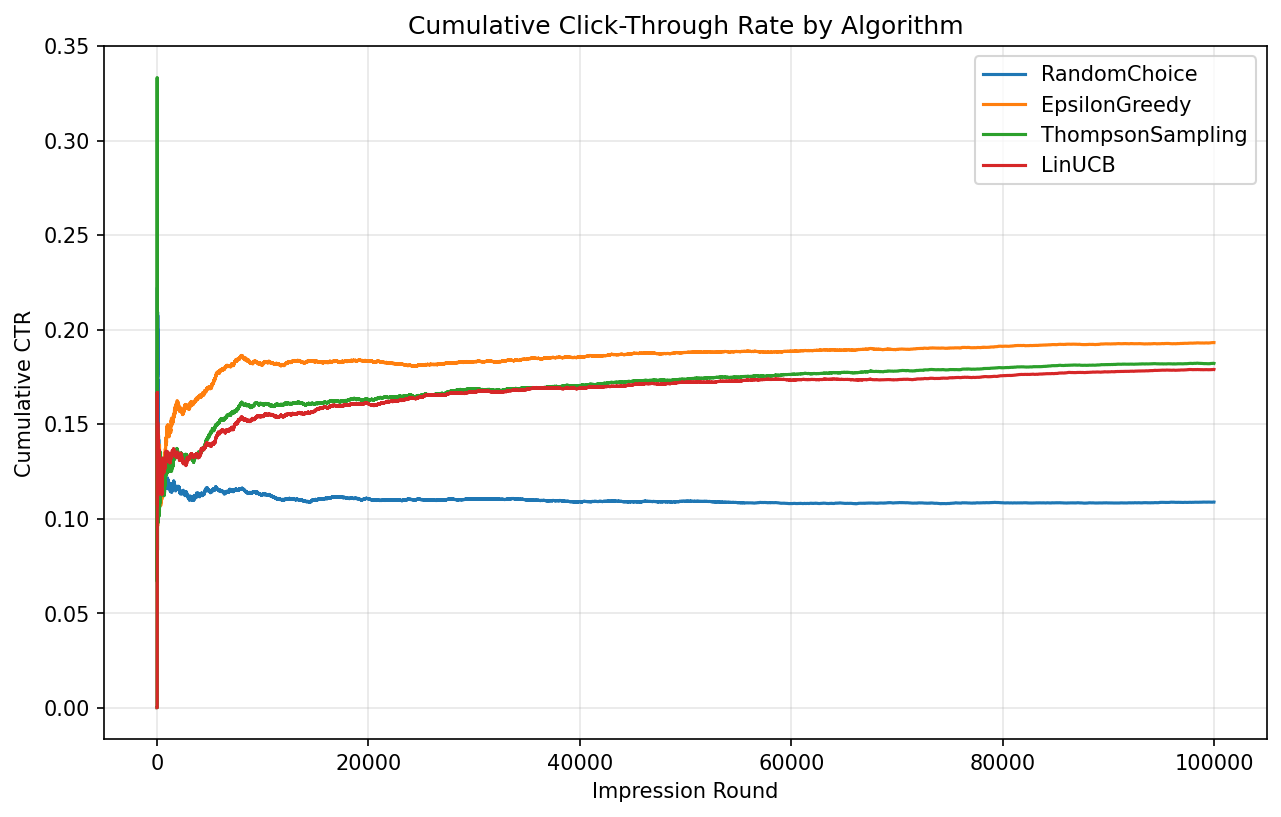
Results
| Algorithm | CTR | vs Random |
|---|---|---|
| RandomChoice | 10.9% | — |
| Epsilon-Greedy | 19.3% | +77% |
| Thompson Sampling | 18.2% | +67% |
| LinUCB | 17.9% | +64% |
Epsilon-greedy won. The simplest learning algorithm beat both Bayesian and contextual approaches.
What I Learned
1. Any learning beats no learning. Even basic epsilon-greedy got 8,400 extra clicks over random. The explore/exploit framework delivers.
2. Simple algorithms are hard to beat. Epsilon-greedy’s fast exploitation of per-article averages crushed it when the same articles kept appearing. Sophistication ≠ better performance.
3. Priors matter for Thompson Sampling. The Beta(1,8) prior (encoding “articles get clicked ~11% of the time”) was crucial. With 18k sparse articles, a uniform prior is too slow.
4. Features make or break contextual bandits. Subcategories > categories. LinUCB’s learning curve was still climbing at 100k impressions—with more data or richer features (title embeddings?), it might win.
5. The framework is the real win. Clean interface (select arm, observe reward, update) makes swapping algorithms trivial. The engineering investment pays off long after any single experiment.
Back to LLM Prompt Shaping
So what does this mean for the LLM application?
First, don’t assume the fanciest algorithm wins. LinUCB lost here, but the dataset favored global popularity over personalization. In conversations, individual differences matter more. A user’s tone shifts within a session. That’s where contextual bandits should shine.
Second, invest in features, not just algorithms. Coarse signals won’t cut it. You need granular conversational context—sentiment trajectory, question density, topic signals, session history. Same lesson as subcategories vs categories.
Third, the modular simulation framework transfers directly. The BanditAlgorithm interface doesn’t care if arms are articles or shaping prompts. Replay conversation logs instead of impressions, score LLM responses instead of clicks, and you’re running the same experiment in a new domain.
I built this as a clean testbed. The real application—teaching LLMs to adapt to you in real time—is next.