Experiment 23
The blog post describes a fork of the DE-ViT algorithm that adapts it for few-shot object detection on satellite imagery by using DINOv3 vision transformers pretrained on the SAT-493M dataset, with a target application of detecting objects in the xView dataset.
Zero-Shot Object Detection for Overhead Imagery: A DE-ViT Adaptation
The DE-ViT Approach
DE-ViT (Detection Transformer with Vision Transformers) represents a significant advancement in few-shot object detection, leveraging the powerful feature representations learned by vision transformers. The approach combines a pretrained vision transformer backbone with a region propagation network to enable detection with minimal training examples. The core innovation lies in how DE-ViT propagates information between support (example) images and query (target) images through a sophisticated attention mechanism, allowing the model to generalize to novel object categories with limited data.
The original DE-ViT architecture employs a subspace projection mechanism to align features from the vision transformer backbone, followed by region proposal generation and a region propagation network that refines detections based on support set prototypes. For a comprehensive understanding of the theoretical foundations, architectural details, and empirical validations, readers are directed to the original research paper.
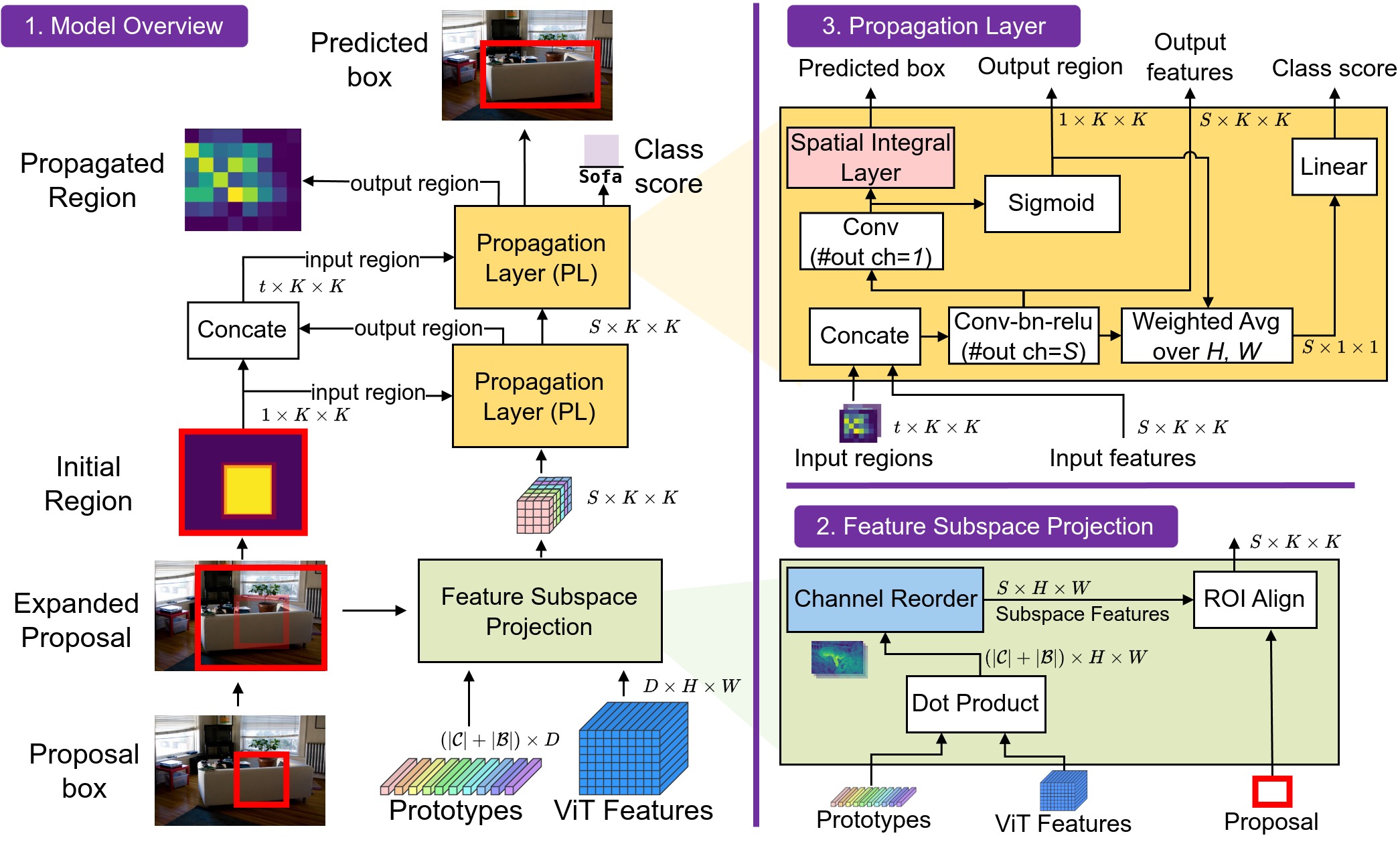 Overview of the DE-ViT method
Overview of the DE-ViT method
Overhead Imagery: Unique Challenges and the xView Dataset
Overhead imagery presents distinct challenges that differentiate it from natural image domains. The most critical challenge is rotation invariance: objects in satellite and aerial imagery can appear at arbitrary orientations, unlike natural images where vehicles are typically upright and buildings follow gravity-aligned perspectives. A car photographed from above may appear at any angle from 0 to 360 degrees, and detection systems must recognize it regardless of orientation.
The xView dataset has become a cornerstone benchmark for evaluating object detection algorithms in overhead imagery. Released in 2018, xView contains over 1 million object instances across 60 categories in high-resolution satellite imagery, spanning diverse geographic regions and imaging conditions. The dataset was specifically designed to challenge computer vision systems with the complexities of overhead imagery: dense object clustering, extreme scale variation (objects ranging from small vehicles to large buildings), and the aforementioned rotation problem.
Historically, xView has driven innovation in several areas: anchor-free detection methods to handle arbitrary orientations, multi-scale feature pyramids to address the extreme scale variation, and attention mechanisms to manage dense scenes. However, most successful approaches have required extensive training on large labeled datasets, limiting their applicability in scenarios where labeled data is scarce or when adapting to new object categories.
 Example image from xView with detections
Example image from xView with detections
Novel Contributions: Toward Zero-Shot Detection
This project introduces several key modifications to the original DE-ViT framework, fundamentally shifting from a few-shot to a zero-shot detection paradigm optimized for overhead imagery.
1. Removal of the Region Propagation Network
The most significant architectural change is the elimination of the region propagation component. While the original DE-ViT uses this network to refine detections through learned interactions between support and query features, this requires training on a base dataset. By removing this component, we transition to a true zero-shot scenario where no training is required. Instead, the system relies entirely on the rich feature representations from the DINOv3 vision transformer, which has been pretrained on 493 million satellite images (SAT-493M dataset). This pretrained knowledge serves as the foundation for detection without any task-specific fine-tuning.
2. Differentiated Prototype Generation
The approach to prototype generation differs fundamentally between base and novel categories:
Base Data Prototypes: For established object categories in the base dataset, prototypes are generated using standard feature extraction and pooling techniques. A large number of examples from each base class is sampled from the training data. Once the DINOv3 features are extracted and pooled, a the KMeans clustering algorithm is used to capture the centers that provide coverage for 75% of the examples. These centers become the prototypes for that base class.
Novel Data Prototypes with Rotation Augmentation: For novel categories where rotation invariance cannot be assumed, the system employs a rotation augmentation strategy. For each image in the few-shot set (e.g. 5), 23 rotations (at 15 degree increments) are created. Next DINOv3 features are calculated and pooled from each of the rotated images. These serve as the novel class prototypes. NOTE: the original orientation of the object is not needed, but at the end of this process it we are guaranteed to have full 360 degree rotation examples.
3. Support Vector Machine Ensemble for Confidence Scoring
The final novel component is the integration of a Support Vector Machine (SVM) ensemble as a confidence gating mechanism. First and SVM is trained to maximally separate the novel classes, base classes, and background. Given a new image, it is rotated using the same scheme from the novel data prototype yielding 24 total images covering all angles. Finally these 24 samples are classified by the SVM and assigned a confidence corresponding to the highest percentage of class agreement (e.g. if 12 of the 24 examples are assigned to background class then it is classified as background with 50% confidence).
This ensemble approach provides several benefits: it captures non-linear decision boundaries that simple cosine similarity cannot, it reduces false positives by requiring consensus across multiple orientations of the target, and it produces calibrated confidence scores that better reflect true match probability. The SVM ensemble acts as a final filter, ensuring that only high-confidence detections propagate to the final output.
Experiment
I did not perform a formal experiment, but here is a rough description of the anecdotal test:
- 2 prototype base classes that cover +70% of xView’s dataset (building & bus)
- 1 background base class
- 1 novel class for testing (excavator)
- 5 full view satellite images with known excavators present
Results
The results were dissapointing. Despite the favorable results published in the paper, the author admits on his Github site that:
[DeVIT] tends to detect objects that do not belong to the prototypes, especially for retailed products that are not presented in the training data. For example, if you have “can”, “bottle”, and “toy” in the scene, but you only have “can” and “bottle” in the class prototypes. The ideal performance is to mark “toy” as background, but DE-ViT tends to detect “toy” as either “can” or “bottle”.
I noticed a similar trend. While the approach is promising for tapping into the power of foundation vision models for few-shot learning, it fails to provide good performance at scale for satellite imagery. I didn’t bother calculating any formal statistics, but you can see for yourself the quality of the classifications below:
(Click to download full resolution) The green boxes are the novel detections (excavators) and blue boxes are classified as one of the base classes. NOTE: the few-shot adaptation did not affect the region proposal network, which was taken from a Faster RCNN model trained on xView, so the bounding box proposals themselves are not part of this evaluation. If you review the contents of the green boxes, however, you will find a low classification accuracy for the excavator class.
Conclusion
This project demonstrates some potential improvements for zero-shot object detection in overhead imagery. Given the results, I cannot recommend the approach without additional changes.
Code for this project can be found at https://github.com/dlfelps/devit-xview.
CLAUDE PROTIPS
In the last few blog posts I provided examples where CLAUDE needed extra guidance. I thought I would do something different in this post.
- PROTIP #1: When working in complex code bases (such as a research level machine learning project), work in small measured steps.
- PROTIP #2: After using CLAUDE to implement a new feature (or in this case replace an existing module with something else), ask CLAUDE to write a simple script to demonstrate/test the new feature. Optional: treat this as a temporary test - you don’t have to add it to git.
- PROTIP #3: If there is a problem that “feels small” and I think I have a good idea how to fix it, I just give CLAUDE the error and CLAUDE will usually fix it.
- PROTIP #4: If there is a problem that “feels big” and I don’t understand it or know how to fix it, I ask CLAUDE to write a debugging script to log values up to the point at which the error occurs. Then I review the output. Next I ask CLAUDE to fix the problem and then run the debugging script again. If all goes well and values make sense I rerun the original code.